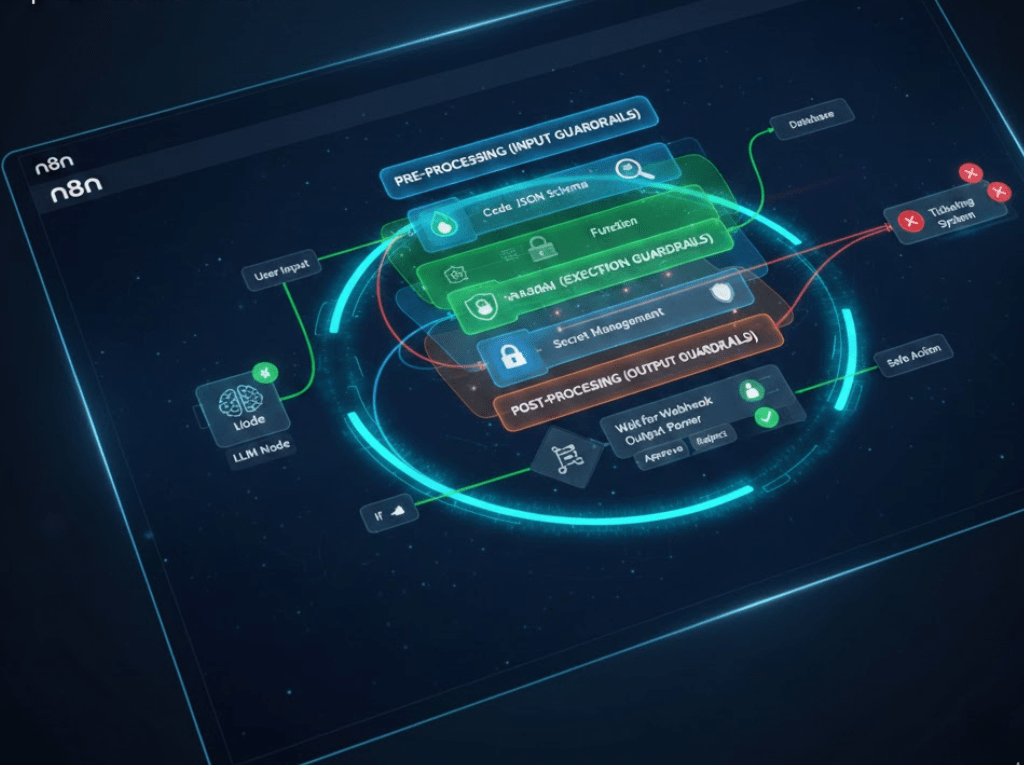
En el salvaje oeste de la automatización generativa, un workflow de n8n sin Guardrails es, básicamente, una invitación abierta al desastre. Si estás conectando LLMs a tus bases de datos o sistemas de tickets, no estás solo construyendo eficiencia; estás construyendo una superficie de ataque.
Como ingenieros, sabemos que el problema no es solo que la IA «alucine», sino que sea manipulada (Prompt Injection) o que filtre datos sensibles (Data Leakage). Aquí te explico cómo levantar un anillo de seguridad profesional dentro de n8n.
La Arquitectura de «Sándwich de Seguridad»
No confíes en el output del LLM, y mucho menos en el input del usuario. La implementación debe seguir un esquema de capas:
- Pre-Processing (Input Guardrails): Sanitización de prompts antes de que lleguen al nodo de IA.
- Processing (Execution Guardrails): Restricciones en el runtime y manejo de secretos.
- Post-Processing (Output Guardrails): Verificación de la respuesta antes de la acción final.
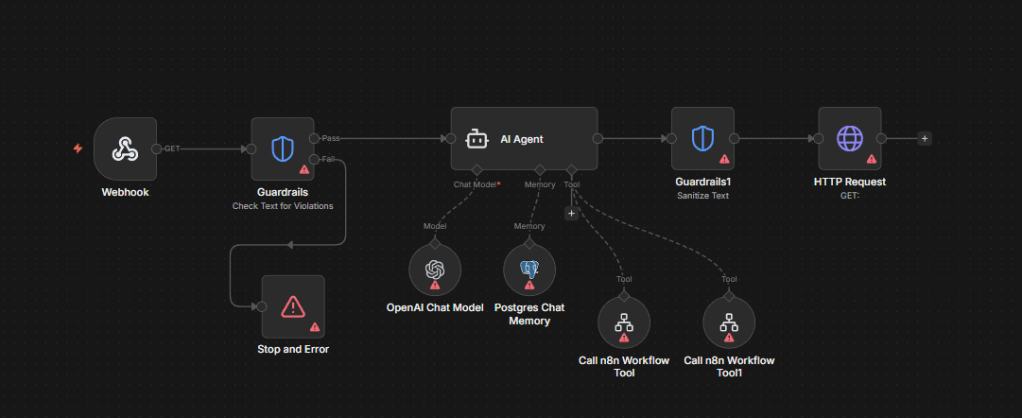
Estrategias de Implementación en n8n
Para que tus flujos pasen una auditoría de seguridad, integra estos tres pilares:
A. Detección de Prompt Injection (Nodo de Código)
Antes de enviar el prompt al nodo de OpenAI o LangChain, usa un nodo de Code con lógica de filtrado o, mejor aún, un clasificador pequeño (como un modelo local en Ollama) que actúe como firewall.
| Amenaza | Técnica de Mitigación en n8n |
| Direct Injection | Uso de nodos de validación de esquemas (JSON Schema). |
| PII Leakage | Regex en nodos de código para detectar y enmascarar emails/DNI. |
| Jailbreaking | Inserción de «System Messages» inmutables que preceden al input del usuario. |
B. Validación de Formato y Lógica (Output Parsing)
Nunca permitas que un LLM ejecute una acción directa (como un HTTP Request de borrado) basado en texto libre.
- Forzado de Esquema: Utiliza el «Output Parser» de LangChain en n8n para obligar al modelo a responder en un JSON estricto.
- El Nodo «If»: Implementa un nodo de control que verifique si el JSON contiene las llaves necesarias antes de pasar a la fase de ejecución.
C. El «Human-in-the-Loop» (HITL)
Para flujos críticos (ej. enviar correos a clientes o modificar infraestructura), el guardrail definitivo es el nodo de Wait for Webhook.
- La IA genera la propuesta.
- n8n envía un mensaje a Slack/Teams con botones de «Aprobar» o «Rechazar».
- El flujo solo continúa tras la validación humana.
El Script de Sanitización (Ejemplo Rápido)
En un nodo de Code, podrías implementar una lógica de «denylist» para palabras clave peligrosas o patrones sospechosos:
JavaScript
const prompt = items[0].json.user_input;
const forbiddenPatterns = [/ignore previous instructions/i, /system prompt/i, /admin access/i];
const isMalicious = forbiddenPatterns.some(pattern => pattern.test(prompt));
if (isMalicious) {
throw new Error(«Intento de manipulación de prompt detectado. Bloqueando ejecución.»);
}
return items;
Implementar Guardrails en n8n no se trata de limitar la IA, sino de definir su radio de explosión. Al separar la lógica de ejecución de la lógica de generación, aseguras que incluso si el modelo es comprometido, el daño colateral sea nulo.
Regla de oro: Trata el output de tu LLM como si fuera el input de un usuario anónimo en internet: nunca es de confianza.

Deja un comentario