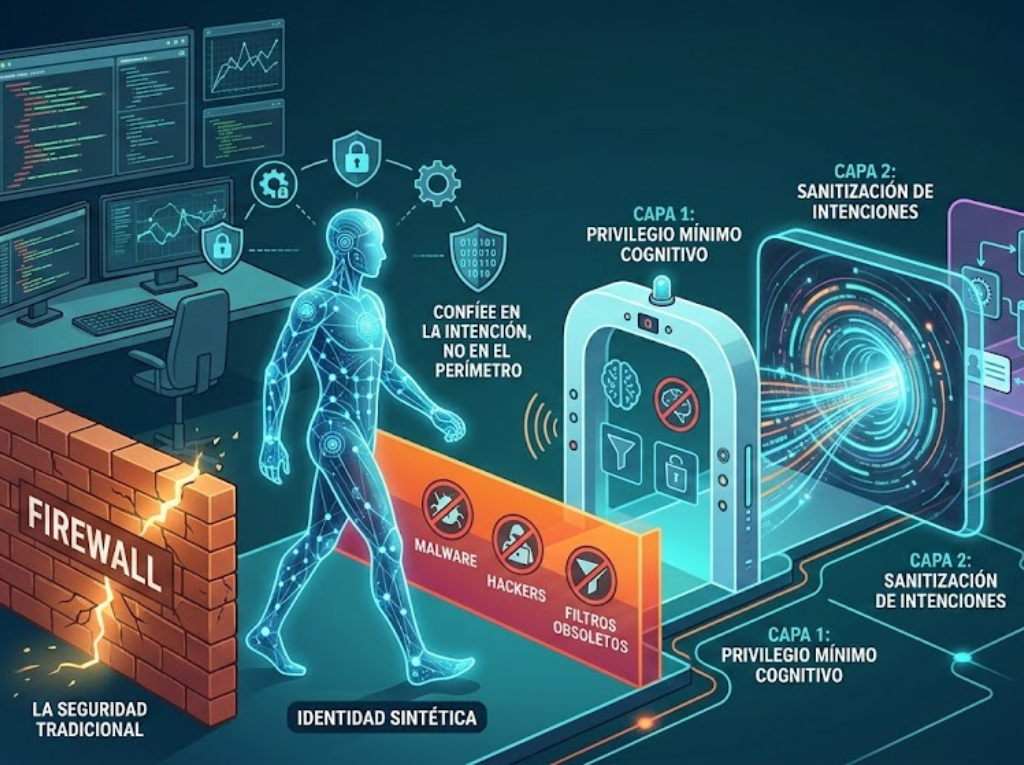
Tradicionalmente, protegemos servidores. Hoy, protegemos intenciones. Un agente de IA no es solo software; es un actor con capacidad de toma de decisiones. Por ello, nuestro framework debe basarse en el principio de Privilegio Mínimo Cognitivo.
Arquitectura de Control: El Modelo «Sandwich»
No confíes en que el LLM se autogobierne. Implementa una estructura de tres capas:
| Capa | Función | Herramientas / Técnica |
| Ingress Guard | Sanitización de prompts y detección de inyecciones (Prompt Injection). | NeMo Guardrails, Llama Guard. |
| Logic Core | El agente operando en un entorno efímero y aislado. | Docker Containers (Stateless), gVisor. |
| Egress Monitor | Validación de outputs y control de llamadas a APIs externas. | DLP (Data Loss Prevention) para agentes. |
Implementación del Framework: Los 3 Pilares Críticos
A. Blindaje contra Inyecciones Indirectas (The Silent Killer)
El mayor riesgo actual no es el usuario malintencionado, sino los datos que el agente lee. Si tu agente resume correos o navega por la web, puede ejecutar instrucciones ocultas en el HTML.
- La Solución: Implementar un Analizador de Contexto Separado. Nunca permitas que las instrucciones del sistema y los datos externos compartan el mismo nivel de confianza en el prompt. Usa delimitadores de alta entropía y validación de tokens.
B. Control de Herramientas (Tool Use & RAG Security)
Si tu agente tiene una función delete_database(), alguien intentará usarla.
- RBAC Dinámico: El agente no debe tener credenciales estáticas. Implementa un sistema de Tokens de Corto Alcance. Cada vez que el agente requiera usar una herramienta, el framework debe validar la intención contra una política de seguridad predefinida antes de liberar el acceso.
C. El «Human-in-the-loop» Selectivo
No todo requiere intervención humana (mataría la escalabilidad), pero las acciones críticas (escritura en DB, envíos de fondos, cambios de configuración) deben pasar por un Checkpoint de Autorización.
«La autonomía de la IA termina donde comienza la integridad del sistema.»
Monitoreo de Deriva Ética y Alucinaciones Adversarias
Los ataques no siempre son crashes; a veces son sutiles manipulaciones del comportamiento.
- Observabilidad Semántica: No monitorices solo logs de CPU; monitoriza el espacio de embeddings. Si los outputs del agente empiezan a desplazarse hacia zonas de riesgo semántico, activa un kill-switch automático.
- Red Teaming Automatizado: Configura un segundo agente (el «Atacante») cuya única misión sea encontrar fallos de lógica en el primer agente de forma continua.
Configurar un framework de seguridad para agentes de IA no es poner una cerradura a una puerta; es diseñar un sistema inmunológico para un organismo digital. En ciberseguridad, la IA es una espada de doble filo: asegúrate de que tú sostienes el mango.

Deja un comentario